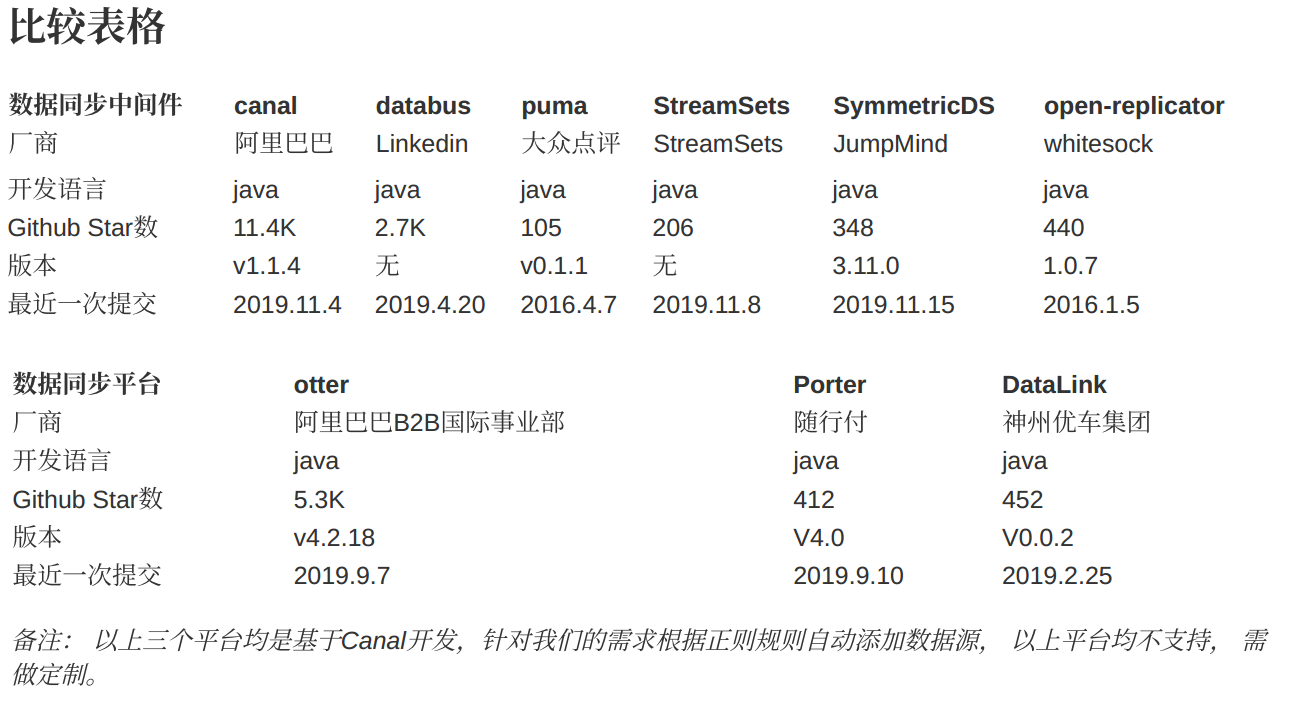
开源数据同步中间件: canal databus puma StreamSets SymmetricDS open-replicator
⼚商: 阿⾥巴巴 Linkedin ⼤众点评 StreamSets JumpMind whitesock
当前的数据同步主要有两种⽅式:
1.准实时同步实现⽅式:
主要有触发器、⽇志解析、基于时间戳这三种⽅式。
(1)基于触发器的⽅式获取数据⽐较传统,并且因为运维繁琐和性能较差等原因,⽤的也越来越少。开源产品
SymmetricDS,可以⾃动化管理触发器并提供统⼀的数据抓取和消费机制,如果想基于触发器做数据同步的话可以使⽤它。
(2)基于⽇志解析的⽅式去做同步⽬前最受⻘睐,像MySQL、HBase等都提供了⽇志重放机制,并且协议开源. 优点是对业务表零侵⼊、异步解析⽇志没有性能问题、实时性⽐较⾼等。
(3)基于时间戳⽇志解析很美好,但并不是所有DB都提供了这样的机制(如SQL Server),当触发器和⽇志解析都搞不定时,通过时间戳字段(如:modify_time)定时扫表,拿到变更数据并进⾏同步,也是常⽤的⼀种⼿段.
缺点:实时性⽐较低、需要业务⽅保证时间戳字段不能出现漏更新,定时扫表查询也可能会带来⼀些性能问题等
2.离线同步实现⽅式:
主要通过Select、⽂件Dump数据(需要⼿⼯导⼊导出)、API抽取等⽅式从源端采集数据。
ETL⼯具基本都是采⽤离线获取数据的⽅式,ETL⼯具解决以下痛点:
1.当数据来⾃不同物理主机,这时⽤SQL语句去处理,就显得⽐较吃⼒且开销也更⼤。
2.数据来源是各种不同的数据库或⽂件,需先把它们整理成统⼀的格式后才能进⾏数据处理,这⼀过程⽤代码实现有些⿇烦。
3.在数据库中可以使⽤存储过程去处理数据,但是处理海量数据时, 存储过程显然⽐较吃⼒,而且会占⽤较多数据库的资源,这可能会导致数据资源不⾜,进而影响数据库的性能。
ETL⼯具可以解决上⾯所说的问题。优点有:
1.⽀持多种异构数据源的连接
2.图形化的界⾯操作⼗分⽅便
3.处理海量数据的速度快,处理的流程也更清晰等等
准实时同步⽅案⽐较:
主要通过Select、⽂件Dump数据(需要⼿⼯导⼊导出)、API抽取等⽅式从源端采集数据。
ETL⼯具基本都是采⽤离线获取数据的⽅式,ETL⼯具解决以下痛点:
1 | 数据同步中间件 canal databus puma StreamSets SymmetricDS open-replicator |
1 | 数据同步平台 otter Porter DataLink |
备注: 以上三个平台均是基于Canal开发,针对我们的需求根据正则规则⾃动添加数据源, 以上平台均不⽀持, 需做定制。
数据同步平台
otter
基于数据库增量⽇志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. ⼀个分布式数据库同步系统。
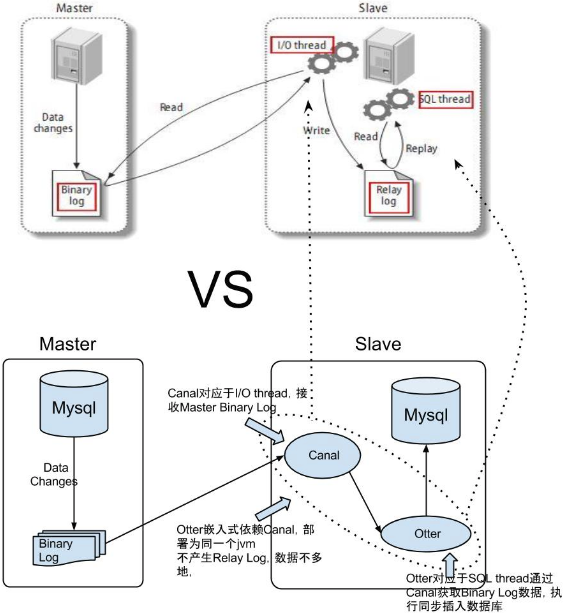
在canal基础上⼜重新实现了可配置的消费者,使⽤otter的话,刚才说过的消费者就不需要写了,而otter提供了⼀个web界⾯,可以⾃定义同步任务及map表。⾮常适合mysql库之间的同步。
与阿⾥巴巴另⼀个开源产品 DataX 的区别:
DataX 主要是解决全量同步,通过select语句或者dump指令提取数据,然后同步到⽬标,数据仓库典型⽤法, 主做离线同步
canal + otter,主要是解决准实时同步,通过解析数据库⽇志,然后同步到⽬标,⽹站前台的典型⽤法。 该⽅案适⽤于⼤规模、扩机房、跨区域等重量级数据同步任务,并具有监控、近实时同步等优点。
otter 的第三个版本是基于SymmetricDS 2.x版本发展出来,正是因为有了这层关系,otter才与SymmetricDS有⼀些相似。
优点:
- 管理&运维⽅便. otter为纯java开发的系统,提供web管理界⾯,⼀站式管理整个公司的数据库同步任务.
- 同步效率提升. 在保证数据⼀致性的前提下,拆散原先Master的事务内容,基于pk hash的并发同步,可以有效提升5倍以上的同步效率.
- ⾃定义同步功能. ⽀持基于增量复制的前提下,定义ETL转化逻辑,完成特殊功能.
- 异地机房同步. 相⽐于mysql异地⻓距离机房的复制效率,⽐如阿⾥巴巴杭州和美国机房,复制可以提升20倍以上. ⻓距离传输时,master向slave传输binary log可能会是⼀个瓶颈.
- 双A机房同步. ⽬前mysql的M-M部署结构,不⽀持解决数据的⼀致性问题,基于otter的双向复制+⼀致性算法,可完美解决这个问题,真正实现双A机房.
限制:
- 暂不⽀持⽆主键表同步. (同步的表必须要有主键,⽆主键表update会是⼀个全表扫描,效率⽐较差)
- ⽀持部分ddl同步 (⽀持create table / drop table / alter table / truncate table / rename table / create index / drop index,其他类型的暂不⽀持,⽐如grant,create user,trigger等等),同时ddl语句不⽀持幂等性操作,所以出现重复同步时,会导致同步挂起,可通过配置⾼级参数:跳过ddl异常,来解决这个问题.
- 不⽀持带外键的记录同步. (数据载⼊算法会打散事务,进⾏并⾏处理,会导致外键约束⽆法满⾜)
- 数据库上trigger配置慎重. (⽐如源库,有⼀张A表配置了trigger,将A表上的变化记录到B表中,而B表也需要同步。如果⽬标库也有这trigger,在同步时会插⼊⼀次A表,2次B表,因为A表的同步插⼊也会触发trigger插⼊⼀次B表,所以有2次B表同步)
架构图: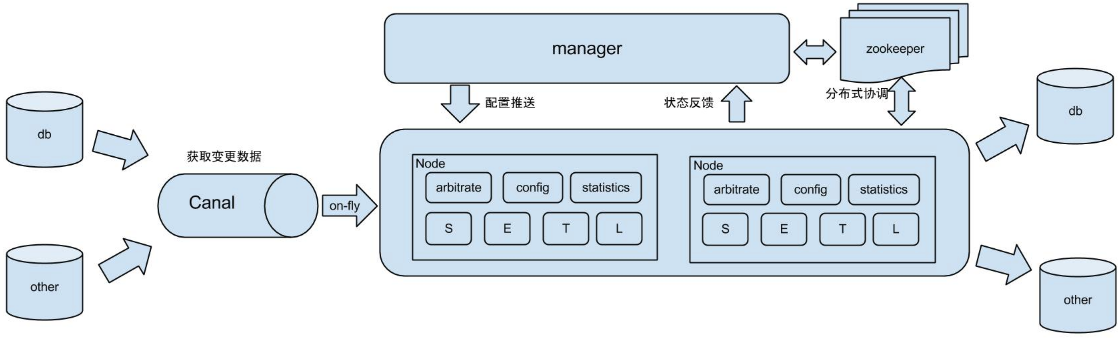
管理界⾯:
Porter
Porter是⼀款数据同步中间件,主要⽤于解决同构/异构数据库之间的表级别数据同步问题, 由随⾏付⽀付公司开源,
使⽤Java语⾔开发. 基于Canal开源产品,获取MySql数据库增量⽇志数据. 基于Oracle GoldenGate, 获取Oracle数据库增量⽇志数据, 类似的还有 yugong(阿⾥巴巴出品) 与阿⾥云提供的DTS平台⾮常类似。
主要提供功能: 数据库准实时同步 数据库迁移 数据库治理 ⾃定义源端、⽬标端数据同步 ⾃定义数据抽取逻辑
核⼼功能: 原⽣⽀持Oracle|Mysql到Jdbc关系型数据库最终⼀致同步 插件友好化,⽀持⾃定义源端消费插件、⽬标端载⼊插件、告警插件等插件⼆次开发 ⽀持⾃定义源端、⽬标端表、字段映射 ⽀持节点基于配置⽂件的同步任务配 置 ⽀持管理后台同步任务推送,节点、任务管理。提供任务运⾏指标监控,节点运⾏⽇志、任务异常告警 ⽀持节点资源限流、分配 基于Zookeeper集群插件的分布式架构, ⽀持⾃定义集群插件.

操作⻚⾯:

DataLink
⼀个满⾜各种异构数据源之间的实时增量同步,分布式、可扩展的数据交换平台. 由神州优⻋集团开源, 基于JAVA开 发。依赖于阿⾥巴巴开源产品 canal.
主要提供功能:
满⾜各种异构数据源之间的实时增量同步 平台提供统⼀的基础设施(⾼可⽤、动态负载、同步任务管理、插件管理、监控报警、公⽤业务组件等等),让设计⼈员专注于同步插件开发,⼀次投⼊,⻓久受益 吸收、整合业内经验,在架构模型、设计⽅法论、功能特性、可运维、易⽤性上进⾏全⾯的升级,在前瞻性和扩展性上下⾜功夫,满⾜未来5-10年内的各种同步需求.
可以⽀撑的应⽤场景有:
ReSharding
BigData
CQRS
EDA
SearchBuild
基础参数共享
实时归档
数据镜像
数据库的迁库、拆库、合库以及灾备等等
原理:
由Task从某⼀个固定类型的数据源读取数据,并同步到若⼲个⽬标端数据源,即为⼀对多的关系。我们将源端数据源类型规定为Task的类型,系统⽬前⽀持的Task类型有:MYSQL, FLEXIBLEQ, HBASE,⽀持同步到的⽬标端数据源类型有:Rdbms、ElasticSearch、Hdfs、HBase、FlexibleQ、SDDL。
概念图:


数据同步中间件
SymmetricDS
SymmetricDS是⽤于数据库复制的开源软件,⽀持单向复制,多主复制, 过滤同步和转换。
基于触发器的数据同步中间件,⽀持多种数据源,⽀持双向同步,⽀持⽂件同步.
触发器安装在数据库中,以确保捕获到数据更改。这意味着应⽤程序将继续照常使⽤数据库,而⽆需任何特殊的驱动 程序软件。触发器被编写为尽可能小而有效。在SymmetricDS流程中,数据的路由和同步在数据库外部完成。
阿⾥巴巴 otter 3.0版本也是参考它实现的。
功能:
不同数据库之间的跨平台数据库复制
本地数据库和云数据库之间的复制
将多个数据库整合到⼀个数据仓库中
区域数据库复制以缩短本地⽤⼾的访问时间
canal
纯Java开发的开源项⽬。基于数据库增量⽇志解析,提供增量数据实时订阅和消费,⽬前主要⽀持了MySQL。
很多⼤型的互联⽹项⽬⽣产环境中使⽤,包括阿⾥、美团等都有⼴泛的应⽤,是⼀个⾮常成熟的数据库同步⽅案,基础的使⽤只需要进⾏简单的配置即可。
当前的 canal 仅⽀持MySQL源端, ⽀持版本: 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
基于mysql的binlog进⾏数据同步的中间件。简单来说,Canal 会将⾃⼰伪装成 MySQL 从节点(Slave),并从主节点(Master)获取 Binlog,解析和贮存后供下游消费端使⽤。

Canal 包含两个组成部分:服务端和客⼾端。服务端负责连接⾄不同的 MySQL 实例,并为每个实例维护⼀个事件消息队列;客⼾端则可以订阅这些队列中的数据变更事件,处理并存储到数据仓库中。
使⽤的话,安装好canal,配置好数据库参数,再编写⼀个客⼾端消费canal传过来的数据就可以了。如何使⽤官⽹写的挺清楚了,可以直接看官⽹。
open-replicator
Open Replicator是⽤Java编写的⾼性能MySQL Binlog解析器。它展现了您可以实时分析,过滤和⼴播⼆进制⽇志事件的可能性。 类似Canal的⼀个产品, Linkin开源的databus中的mysql模块⽤到了这个项⽬。
Puma
设计宗旨:
数据库增量数据100%⼀致性的保证
为了100%数据⼀致性的保证,会在极少数时候出现极少数数据的重复,需要业务保证幂等操作
⾼实时性保证,同⼀机房延时控制在1s以内
⾯向数据库层⾯设计,而⾮数据库实例层⾯(与业务的隔离性保持相同)
⾼可⽤性,各个边界上都有ha⽅案的保证
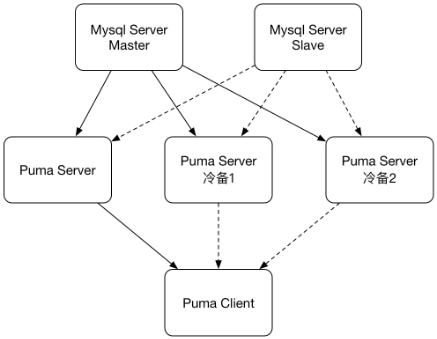
原理:
Puma服务器伪装成Mysql Slave节点,连接上Mysql服务器,接收binlog⽇志
Puma服务器解析,过滤并存储数据库的增量变化
Puma客⼾端连接到Puma服务器,进⾏数据库增量的消费
⽀持范围:
Puma⽬前只⽀持Mysql数据库,后续会加⼊对于其他数据库的⽀持
Mysql⽀持5.1 - 5.6版本,后续会对5.7版本进⾏⽀持
Databus
Databus是⼀个实时的低延时数据抓取系统。它将数据库作为唯⼀真实数据来源,并将变更从事务或提交⽇志中提取出来,然后通知相关的衍⽣数据库或缓存。 Databus 的传输层端到端延迟是微秒级的,每台服务器每秒可以处理数千次数据吞吐变更事件,同时还⽀持⽆限回溯能⼒和丰富的变更订阅功能。概要结构如下图:
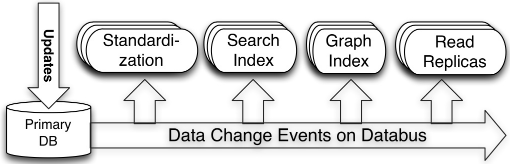
图中显⽰:Search Index 和 Read Replicas 等系统是 Databus 的消费者。当主 OLTP 数据库发⽣写操作时,连接其上的中继系统会将数据拉到中继中。签⼊在 Search Index 或是缓存中的 Databus 消费者客⼾端,就会从中继中拉出数据,并更新索引或缓存.
⽬前databus的主要应⽤:
1.是主数据库和衍⽣数据库的同步,⼀般是为了对主数据库数据按另外维度进⾏组织,提供给查询使⽤
2.是⽤来将数据库数据同步到缓存中,这样主要是为了减轻数据库读压⼒。
解决⽅案的决策过程:
1.程序实现双写:
在此模型中,应⽤程序层写⼊数据库,然后并⾏写⼊另⼀个消息传递系统。这看起来很容易实现,因为将应⽤程序代码写⼊数据库是在我们的控制之下。 但是,由于没有复杂的协调协议(例如Paxos或2-Phase Commit),很难确保数据库和消息传递系统在⾯对故障时彼此完全锁定,因此会带来⼀致性问题。
2.基于数据库⽇志⽂件: 将数据库作为唯⼀真实数据来源,并将变更从事务或提交⽇志中提取出来。这可以解决⼀致 性问题,但是很难实现,因为 Oracle 和 MySQL 有私有的交易⽇志格式和复制冗余解决⽅案,难以保证版本升级之后的可⽤性。由于要解决的是处理应⽤代码发起的数据变更,然后写⼊到另⼀个数据库中,冗余系统就得是⽤⼾层⾯的,而且要与来源⽆关。对于快速变化的技术公司,这种与数据来源的独⽴性⾮常重要,可以避免应⽤栈的技术锁定,或是绑死在⼆进制格式上。
在评估了两种⽅式的优劣之后,我们决定选择⽇志挖掘,将⼀致性和单⼀真实数据来源作为最⾼优先级,而不是易于 实现。
提供以下功能:
⽀持多种数据来源的变更抓取,包括 Oracle 和 MySQL。
可扩展、⾼度可⽤:Databus 能扩展到⽀持数千消费者和事务数据来源,同时保持⾼度可⽤性。
事务按序提交:Databus 能保持来源数据库中的事务完整性,并按照事务分组和来源的提交顺寻交付变更件。
低延迟、⽀持多种订阅机制:数据源变更完成后,Databus 能在微秒级内将事务提交给消费者。同时,消费者
使⽤ Databus 中的服务器端过滤功能,可以只获取⾃⼰需要的特定数据。
⽆限回溯:这是 Databus 最具创新性的组件之⼀,对消费者⽀持⽆限回溯能⼒。当消费者需要产⽣数据的完
整拷⻉时(⽐如新的搜索索引),它不会对主 OLTP 数据库产⽣任何额外负担,就可以达成⽬的。当消费者
的数据⼤⼤落后于来源数据库时,也可以使⽤该功能。

粗略的来说databus主要模块是两个,⼀个是relay,负责从mysql/oracle拉取变更事件,并存储到本地的内存buffer;
⼀个是client,负责从relay拉取变更事件,并做业务定制化的处理。 上⾯的图⽚是Databus的⼤致架构,可以看到包括中继Relay、Bootstrap服务和客⼾端库三⼤模块;其中Bootstrap包括BootStrap Producer和BootStrap Server。快速变化的消费者从relay中拉取数据,但如果⼀个消费者的数据⼤幅度落后,relay就不能提供它要的数据,转而由Bootstrap Producer提供给它⾃上次处理后变更的所有数据快照。下⾯来具体的介绍下这⼏个模块的主要功能:
Databus Relay中继主要功能:
从Databus来源读取变更⾏,并在内存缓存中将其序列化为DataBus事件。 监听来着Databus客⼾端(包括Bootstrap)的请求,并传输新的Databus变更事件
Databus客⼾端的功能主要包括:
检查Relay上新的数据事件的变更,并执⾏特定业务逻辑的回调 如果落后Relay太多,则向BootStrap Server发起查询新的DataBus客⼾端会先向BootStrap Server发起bootstrap查询,然后再切换到向中继发起查询,以完成最新的数据 变更 单⼀客⼾端可以处理整个Databus数据流,或者可以成为消费者集群的⼀部分,其中每个消费者只处理⼀部分流数据
Bootstrap Server可以看成⼀种特定的Databus客⼾端,它的功能有:
监听中继数据变⾰ 将变更存储到mysql数据库中 mysql数据库供Bootstrap和客⼾端使⽤ Databus Bootstrap Server的
主要功能,就是监听来⾃Databus客⼾端的请求,并返回⻓期回溯数据变更事件。
参考:
https://yq.aliyun.com/articles/85407
StreamSets
Streamsets是⼀个⼤数据实时采集ETL⼯具,可以实现不写⼀⾏代码完成数据的采集和流转。通过拖拽式的可视化界⾯,实现数据管道(Pipelines)的设计和定时任务调度。 数据源⽀持MySQL、Oracle等结构化和半/⾮结构化,⽬标源
⽀持HDFS、Hive、Hbase、Kudu、Solr、Elasticserach等。创建⼀个Pipelines管道需要配置数据源(Origins)、操作 (Processors)、⽬的地(Destinations)三部分。
Streamsets的强⼤之处:
拖拽式可视化界⾯操作,No coding required 可实现不写⼀⾏代码
强⼤整合⼒,100+ Ready-to-Use Origins and Destinations,⽀持100+数据源和⽬标源
可视化内置调度监控,实时观测数据流和数据质量
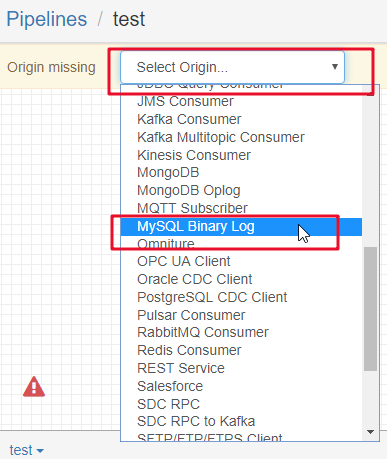
原理:
StreamSets 数据收集器是⼀个轻量级,强⼤的引擎,实时流数据。使⽤Data Collector在数据流中路由和处理数据。 要为Data Collector定义数据流,请配置管道。⼀个流⽔线由代表流⽔线起点和终点的阶段以及您想要执⾏的任何附加处理组成。配置管道后,单击“开始”,“ 数据收集器”开始⼯作。 Data Collector在数据到达原点时处理数据,在不需要时静静地等待。您可以查看有关数据的实时统计信息,在数据通过管道时检查数据,或仔细查看数据快照。
离线同步⽅案
离线同步⽅案基本上是⽤开源的ETL⼯具, 这⾥集中调研了开源免费的ETL⼯具。
ETL⼯具中, kettle、DataStage、Informatica 这三⼤⼯具依旧牢牢稳固传统数仓三⼤主⼒位置, 占据国内市场的⼤部分的份额, 看ETL⼯程师招聘要求可知.
Datastage和Informatica是商业⼯具,价格不菲。 kettle 是最著名的开源产品,纯Java编写的ETL⼯具, 免费。
下表是开源ETL⼯具⽐较:
⽐较维度 kettle talend datax
使⽤⽅式
开发和⽣产环境需独⽴部署, 任
务的编写,调试,修改都在本地
需发布到⽣产环境,⽣产没有界
⾯,需要通过⽇志调试
开发和⽣产环境需独⽴部署, 任务
的编写,调试,修改都在本地
需发布到⽣产环境
以脚本的⽅式执⾏任务,需熟悉源码才能调
⽤,没有图形化开发界⾯和监控界⾯。
底层
框架
主从结构⾮⾼可⽤,不适合⼤数
据场景 ⽀持分布式部署 ⽀ 署持 ⽅单 式机和集群(通过调度平台规避)两种部
CDC
机制 基于时间戳、触发器 基于时间戳、触发器、⾃增序列 离线批处理
监控
告警
依赖⽇志定位故障,缺少过程预
警 有问题预警,定位问题依赖⽇志 依 ⾯赖 和⼯ 预具 警⽇ 机志 制定 ,位 需故 ⾃障 定, 义没 开有 发图形化运维界
数据
清洗
围绕数据仓库的数据需求进⾏建
模计算,需⼿动编程 ⽀持复杂罗辑清洗和转化 需根据⾃⾝规则编写清晰脚本,进⾏调⽤
数据
转换 ⼿动配置scheme mapping ⼿动配置scheme mapping 编写json⽂件进⾏定义
kettle
kettle痛点:
1.全量抽取较⼤数据量时,抽取时间⻓ 2.往hdfs导数据出现漏导的情况,造成数据不⼀致 3.⽆法感知namenode的切
换,当Hadoop集群重启时,⼀旦namenode发⽣切换,就可能造成kettle任务的失败,因为kettle的hdfs地址是在配置
⽂件中配置的 4.kettle往Greenplum中导数据,速度⾮常慢(40条每秒)
Datax
1.Datax作为⼀种ETL⼯具,还是⽐较简单的,不仅是配置简单,而且Datax的错误⽇志也很智能化,我们排错的时候
也会⽐较⽅便 2.Datax适合于直连⽅式的数据同步。对于数据⽂件⽅式的同步,需要我们⾃⼰去维护数据的字段信
息,配置起来⽐较繁琐,没有kettle⽅便 3.Datax⽬前也是不⽀持namenode切换的动态感知 4.Datax的⼯作流需要依
托于调度⼯具的流,本⾝并不具备⼯作流特性
DataX是由Alibaba开源的⼀款异构数据同步⼯具,可以在常⻅的各种数据源之间进⾏同步,并仅依赖Java环境,具
有轻量、插件式、⽅便等优点,可以快速完成同步任务。⼀般公司的数据同步任务,基本可以满⾜。
参考:
https://dbaplus.cn/news-141-2315-1.html
https://www.ctolib.com/topics-96532.html#articleHeader10
https://anjia0532.github.io/2019/06/10/cdh-streamsets/